Hinweis: Dieser Artikel ist älter als 3 JahreInhalte, Quelltexte oder Links können zwischenzeitlich überholt sein.
25. Oktober 2020, 12:22Lesezeit: ca. 3 Min
Whitebox-Monitoring mit Prometheus
Winter is coming! Die Winterzeit ist bereits da, der Corona-Lockdown demnächst auch.
Da ist es ein gutes Gefühl daheim im Warmen zu sitzen und die IT vollständig im Überblick zu haben. Das Stichwort heisst hier “vollständig”, denn ich setze beim Server-Monitoring nicht auf klassische Blackbox-Lösungen1 sondern auf die Whitebox-Lösung Prometheus2.
Hinter Prometheus sitzt kein einzelnes Unternehmen sondern eine Initiative verschiedener Unternehmen. Das Who-is-Who der Branche mit RedHat, Amazon, Apple, ARM und vielen anderen3. Selbstverständlich steht Prometheus unter einer freien Lizenz und ist vollständig Open-Source.
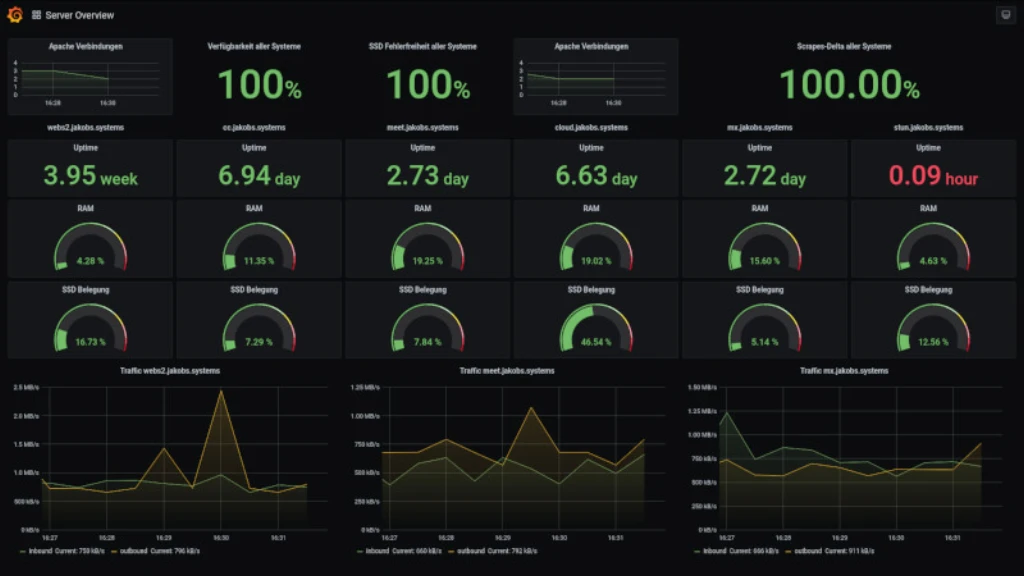
Bitte nicht von den schönen Grafana-Dashboards4 meiner eigenen Infrastruktur täuschen lassen. Die Screenshots zeigen nur wie ein Ausfall sich visuell bei mir äußert. Das bekommt jeder mit einer anderen Monitoring-Lösung auch hin. Was Prometheus ausmacht sind die Graphen, Vektoren und Timeserien hinter dem Eye-Candy.
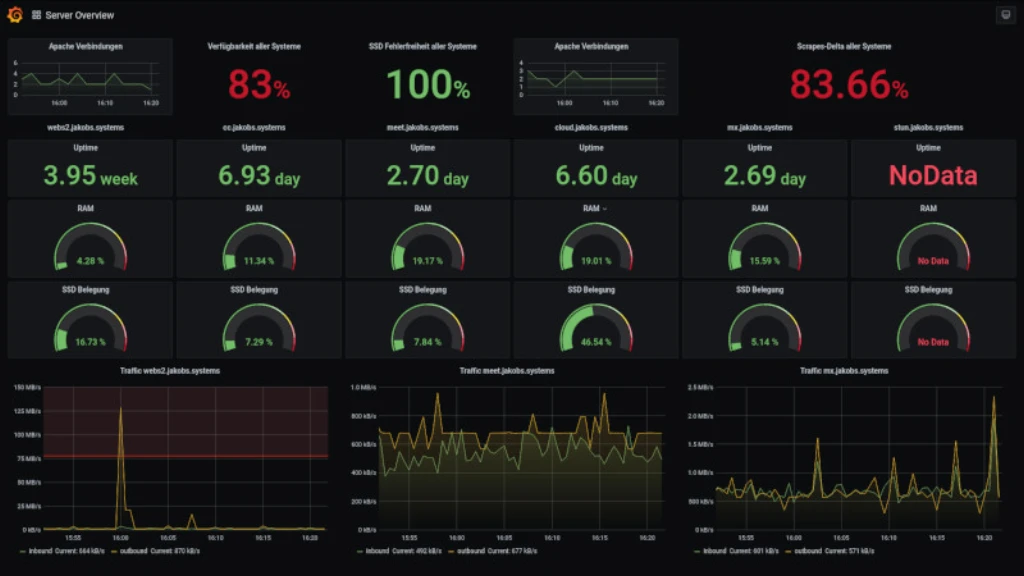
Die drei Zustände für einen Host bzw. die vier Zustände für einen Dienst in einem Icinga2 reichen bestenfalls nur für ein Alerting aus. Für viele ausreichend, für mich nicht!
Ist es nicht intelligenter, auf ein Ereignis nicht nur zu reagieren sondern auch zu wissen, wie es entstand? Lassen sich proaktiv Ereignisse erkennen und möglicherweise verhindern? Spoiler: Ja!
Prometheus zählt zu den Whitebox-Monitoring Lösungen, die genau das ermöglichen. Es arbeitet nicht log- oder ereignisorientiert sondern mit Graphen und Zeitserien. Vereinfacht gesagt ähneln die Meßwerte Countern, die auf einer Zeitachse festgehalten werden. Während ein Icinga2 aktiv einzelne Werte abfragt und andere nur Round-Robin laufen, pullt5 Prometheus durch seine HTTP-Abfragen gleich hunderte oder gar tausende von Metriken. Erstaunlicherweise ohne dabei ein höhere Last auf den Hosts oder im Netzwerk zu erzeuzgen. Durch seinen föderierten Aufbau skaliert es sogar deutlich besser als jeder zentralisierte Ansatz.6
Ein Beispiel: Icinga2 pingt in Minutenintervallen einen bestimmten Dienst an, der mit einer Antwort reagiert. Wenn 10 Sekunden zuvor der Dienst jedoch durch eine Anfrage blockiert war und 10 Sekunden danach erneut, ist für den Icinga2 die Welt in Ordnung während beim 1st-Level bereits die Telefone klingeln.
Als Softwareentwickler gefallen mir die mehrdimensionale Abfragen in Prometheus mit der Abfragesprache PromQL sehr. Das Tagging von Metriken oder das Einbinden von Webhooks bietet einen Einblick tief hinein in Microservices und Drittanwendungen. Im nachfolgenden Screenshot ist eine solche PromQL-Abfrage über meinen Email-Server mx.jakobs.systems zu sehen.
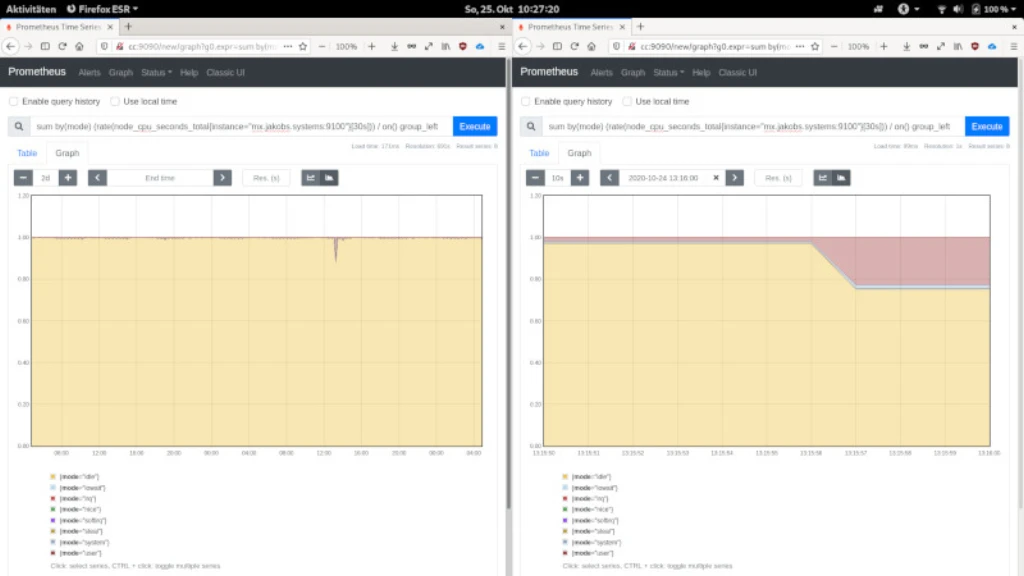
Es werden alle 8 Datenpunkte aller 4 CPUs über die Zeit abgefragt. Wir reden hier von einer Abfrage über hunderttausende, wenn nicht sogar Mio von Datenpunkten, die in 171 ms auf einer kleinen Intel 2-Core NUC beantwortet werden. Das schafft kein klassisches, relationales DBMS/PHP System. Links die Ergebnisse über 2 Tage, rechts hineingezoomt bis auf eine Sekunde genau.
Alle Kunden mit von mir betreuten “managed” Cloud-, Web- oder Konferenzservern sind automatisch im Monitoring enthalten. Kunden mit festen Netzwerk-Supportverträgen erhalten ab 1. Januar 2021 bei Stellen eines geeigneten Systems (SSH-Zugang zu VM oder bare-metal), eine kostenlose Installation inkl. Einbindung aller bare-metal Server im gleichen Netzwerksegment und eines entsprechenden Grafana-Dashboards.
Übrigens: Das Scrapen von Logdaten sollte - obwohl möglich7 - nicht mit Prometheus gemacht werden. Das hat etwas von “mit-einem-Porsche-GT4-zum-Wocheneinkauf” fahren wollen. Dieses Unterfangen sollte generell mit keiner Monitoring-Anwendung versucht werden. Für diesen Job gibt es bessere Tools wie z.B. ElasticSearch.
Aus Datenschutzgründen verzichte ich bewusst auf ein dauerhaftes Speichern solcher Logdaten. Die meisten werden nach 24h bereits gelöscht, einzelne je nach SLA später.